Temporal super-resolution
Our model could be used to increase the frame rate of videos - by simply interpolating between the estimated trajectories between two video frames.
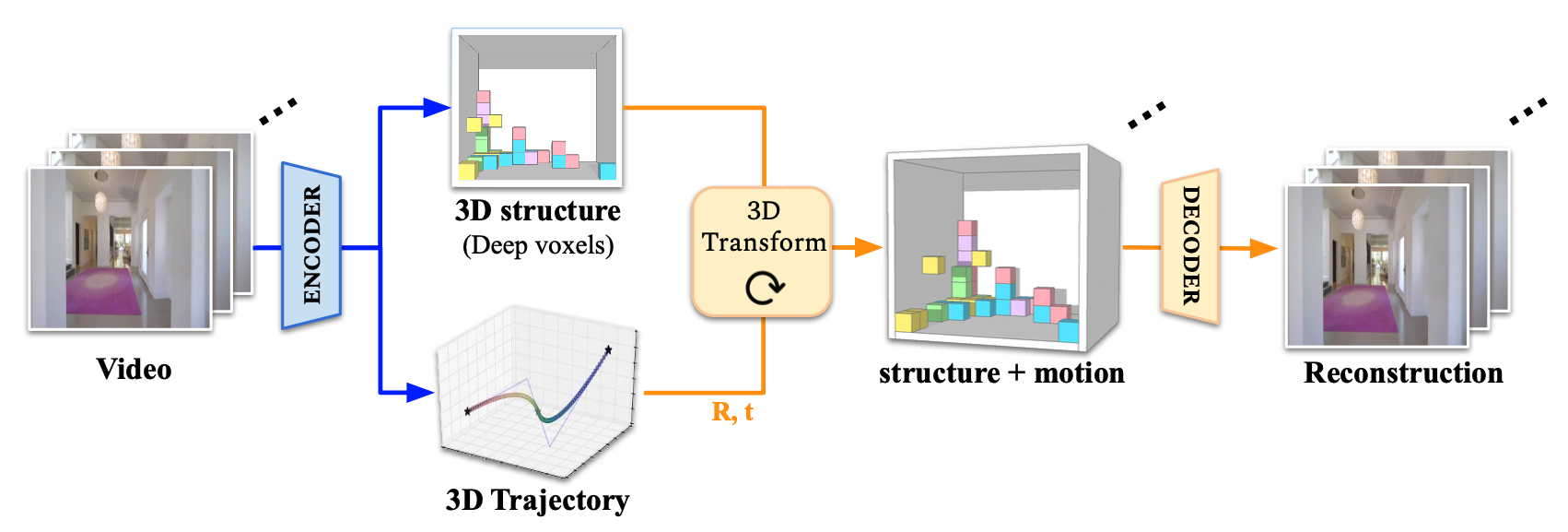
We present Video Autoencoder for learning disentangled representations of 3D structure and camera pose from videos in a self-supervised manner. Relying on temporal continuity in videos, our work assumes that the 3D scene structure in nearby video frames remains static. Given a sequence of video frames as input, the Video Autoencoder extracts a disentangled representation of the scene including: (i) a temporally-consistent deep voxel feature to represent the 3D structure and (ii) a 3D trajectory of camera poses for each frame. These two representations will then be re-entangled for rendering the input video frames. Video Autoencoder can be trained directly using a pixel reconstruction loss, without any ground truth 3D or camera pose annotations. The disentangled representation can be applied to a range of tasks, including novel view synthesis, camera pose estimation, and video generation by motion following. We evaluate our method on several large-scale natural video datasets, and show generalization results on out-of-domain images.
The proposed Video Autoencoder is a conceptually simple method for encoding a video into a 3D representation and a trajectory in a completely self-supervised manner (no 3D labels are required).
Our model could be used to increase the frame rate of videos - by simply interpolating between the estimated trajectories between two video frames.
Here, we "stabilize" all video frames to a fixed viewpoint. With Video Autoencoder, we can simply warp the whole video to the first frame with the estimated pose difference.
Our model could also work for out-of-distribution data such as anime scenes, Spirited Away.
Video Autoencoder could generate results as if we are walking into Vincent van Gogh’s bedroom in Arles.
We can also estimate trajectory in videos. For each video clip, we can estimate the relative pose between every two video frames and chain them together to get the full trajectory.
Our model can also animate a single image (shown left) with the motion trajectories from a different video (shown in the middle). We call this video following.
@inproceedings{Lai21a,
title={Video Autoencoder: self-supervised disentanglement of 3D structure and motion},
author={Lai, Zihang and Liu, Sifei and Efros, Alexei A and Wang, Xiaolong},
booktitle={ICCV},
year={2021}
}